

Tổng quan :
Trong môi trường số hóa ngày nay, bảo vệ thông tin cá nhân và dữ liệu nhạy cảm đang trở thành một nhiệm vụ thiết yếu. Data Masking, một phương pháp quan trọng trong lĩnh vực bảo mật dữ liệu, đã nổi lên như một biện pháp quan trọng để đảm bảo tính riêng tư và an toàn cho dữ liệu. Trong bài viết này, chúng ta sẽ khám phá sâu hơn về khái niệm Data Masking, cùng với các loại hình ứng dụng khác nhau, kỹ thuật điển hình và những thực tiễn tốt nhất liên quan. Bằng cách hiểu rõ về các khía cạnh này, chúng ta có thể xây dựng một cơ sở vững chắc để bảo vệ dữ liệu quan trọng và tuân thủ các quy định bảo mật dữ liệu đang ngày càng chặt chẽ hơn.
Nội dung bài viết :
1. Data Masking là gì ?

Data masking là một phương pháp được sử dụng trong quản lý dữ liệu để bảo vệ thông tin nhạy cảm. Nó liên quan đến việc che giấu thông tin cá nhân, nhạy cảm hoặc quan trọng trong các tập dữ liệu sao cho dữ liệu này vẫn có thể sử dụng cho mục đích phân tích, kiểm thử hoặc phát triển mà không làm lộ ra thông tin nhạy cảm.
Cách thức hoạt động của data masking thường bao gồm việc thay thế, mã hóa hoặc che đi một phần hoặc toàn bộ dữ liệu nhạy cảm bằng dữ liệu giả mạo hoặc dữ liệu đã được biến đổi. Mục tiêu là để người dùng có thể làm việc với dữ liệu mà không thể xác định được thông tin cá nhân hoặc nhạy cảm.
Ví dụ, khi làm việc với dữ liệu thử nghiệm trong môi trường phát triển, bạn có thể sử dụng data masking để che giấu thông tin nhạy cảm như số thẻ tín dụng, thông tin tài khoản ngân hàng, số CMND, v.v. thay vào đó là dữ liệu mẫu hoặc dữ liệu đã được biến đổi mà vẫn giữ nguyên cấu trúc tổng thể của dữ liệu.
Data masking giúp tăng cường bảo mật dữ liệu và đảm bảo rằng dữ liệu nhạy cảm không bị lộ ra ngoài trong quá trình phát triển, kiểm thử hoặc phân tích.
2. Tạ sao Data Masking lại đóng vai trò quan trọng

Trong bối cảnh quy định về bảo vệ và an ninh dữ liệu ngày càng trở nên cấp bách, Data Masking ngày nay đóng một vai trò quan trọng trong việc đáp ứng các yêu cầu bảo mật cốt yếu.
Dưới đây là một số lí do mà Data Masking đã trở thành một yêu cầu chủ yếu đối với nhiều tổ chức:
- Giảm thiểu các mối đe dọa nghiêm trọng như mất dữ liệu, sự rò rỉ dữ liệu, nguy cơ từ người bên trong và tài khoản bị xâm nhập.
- Giảm nguy cơ liên quan đến dữ liệu khi sử dụng đám mây.
- Biến dữ liệu trở thành vô dụng đối với kẻ tấn công, trong khi vẫn giữ nguyên nhiều tính năng cơ bản của dữ liệu.
- Cho phép chia sẻ dữ liệu với người dùng có quyền, chẳng hạn như các nhà kiểm thử và nhà phát triển, mà không tiết lộ dữ liệu sản xuất nhạy cảm.
- Có thể sử dụng để làm sạch dữ liệu. Trong khi việc xóa tệp thông thường vẫn để lại dấu vết dữ liệu trên phương tiện lưu trữ, việc làm sạch thay thế các giá trị cũ bằng những giá trị được che đậy.
- Data Masking là một yêu cầu của nhiều quy định về bảo mật dữ liệu. Ngay cả khi không có sự cố liên quan đến dữ liệu tại tổ chức của bạn, việc tuân thủ các quy định vẫn là điều cần thiết.
3. Một số định dạng Data Masking
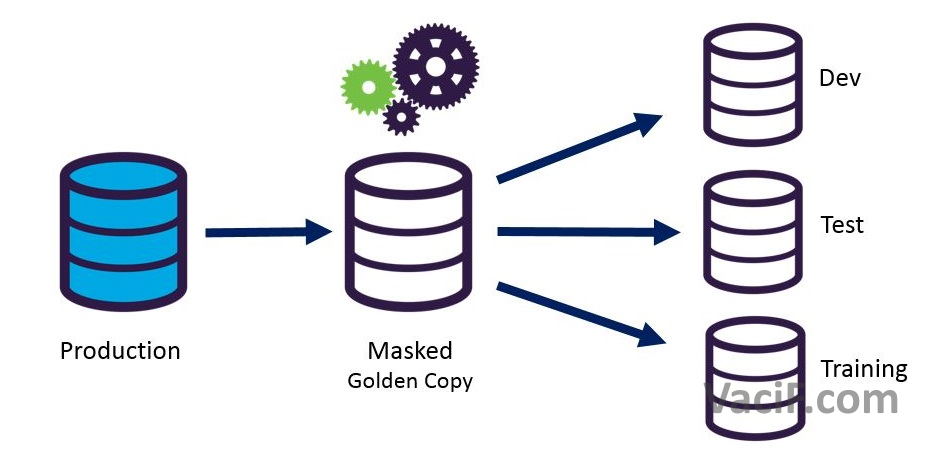
- Data Masking: Data masking là một kỹ thuật được sử dụng để bảo vệ thông tin nhạy cảm bằng cách thay thế dữ liệu gốc bằng dữ liệu giả tạo, hoán đổi hoặc ẩn danh. Điều này đảm bảo rằng dữ liệu vẫn hoạt động cho các mục đích khác nhau trong khi giảm nguy cơ tiết lộ thông tin nhạy cảm cho người dùng không được ủy quyền.
- Static Data Masking (SDM): Static data masking liên quan đến việc thay đổi dữ liệu nhạy cảm theo cách không thay đổi và vĩnh viễn. Thông thường, điều này được thực hiện trên một bản sao của dữ liệu gốc. Dữ liệu đã được ẩn danh vẫn giữ định dạng và cấu trúc giống như ban đầu, nhưng thông tin nhạy cảm được thay thế bằng dữ liệu giả tạo có vẻ thực tế. Phương pháp này hữu ích cho mục đích phát triển, kiểm thử và phân tích trong khi duy trì quyền riêng tư của dữ liệu.
- In-Place Masking: In-place masking là quá trình thay đổi dữ liệu nhạy cảm trực tiếp trong môi trường sản xuất mà không tạo ra một bản sao riêng của dữ liệu. Kỹ thuật này yêu cầu thận trọng để đảm bảo quá trình ẩn danh không gây gián đoạn cho hoạt động của các ứng dụng sử dụng dữ liệu.
- On-the-Fly Masking: On-the-fly masking liên quan đến việc áp dụng các kỹ thuật ẩn danh dữ liệu theo thời gian thực khi dữ liệu được truy cập hoặc truy xuất. Điều này đặc biệt hữu ích cho các tình huống khi dữ liệu nhạy cảm cần được bảo vệ trong quá trình sử dụng, chẳng hạn như trong giao tiếp ứng dụng hoặc báo cáo.
- Dynamic Data Masking: Dynamic data masking là một kỹ thuật liên quan đến việc biến đổi dữ liệu theo thời gian thực và có thể đảo ngược vào thời điểm truy vấn dữ liệu. Nó cho phép người dùng được ủy quyền xem dữ liệu gốc, nhưng thông tin nhạy cảm được ẩn danh đối với người dùng không được ủy quyền. Kỹ thuật này thường được sử dụng để bảo vệ dữ liệu trong môi trường sản xuất trong khi duy trì tính toàn vẹn của dữ liệu gốc.
- Synthetic Data Generation: Synthetic data generation liên quan đến việc tạo ra dữ liệu hoàn toàn mới và giả tạo mô phỏng các đặc điểm của dữ liệu thực. Dữ liệu này có thể được sử dụng cho các mục đích khác nhau, bao gồm kiểm thử, huấn luyện mô hình học máy và chia sẻ với bên thứ ba, mà không đặt dữ liệu nhạy cảm thực sự trong tình thế nguy hiểm. Các kỹ thuật tạo dữ liệu giả tạo nhằm duy trì các tính chất thống kê của dữ liệu gốc trong khi đảm bảo không có dữ liệu nhạy cảm thực sự tồn tại.
Những kỹ thuật ẩn danh dữ liệu này đóng vai trò quan trọng trong việc bảo vệ thông tin nhạy cảm và duy trì quyền riêng tư và bảo mật dữ liệu, đặc biệt trong các môi trường cần chia sẻ dữ liệu, phân tích hoặc kiểm thử mà không đặt dấu hỏi cho tính bảo mật của dữ liệu gốc. Mỗi kỹ thuật có ưu điểm và ứng dụng riêng của nó, phụ thuộc vào yêu cầu và ràng buộc cụ thể của tình huống.
4. Các dạng kỹ thuật Data Masking
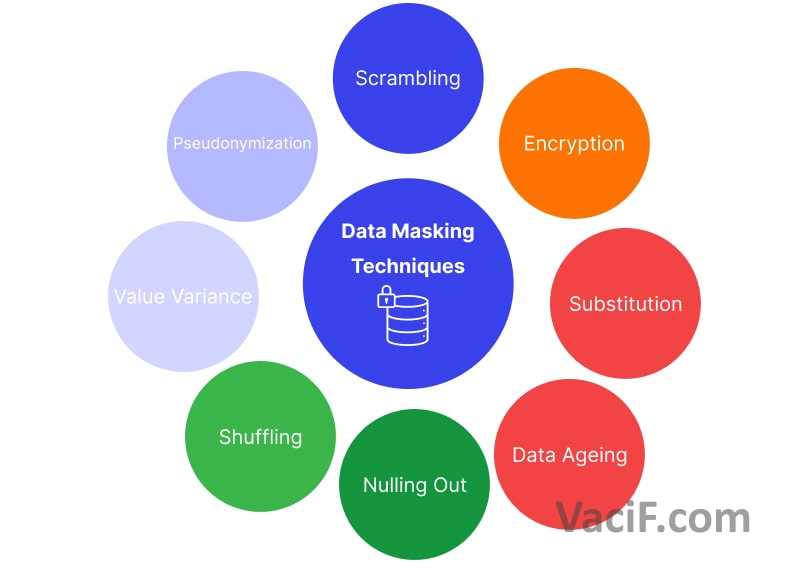
Có nhiều cách khác nhau để thực hiện Data Masking, bao gồm:
- Xáo trộn (Scrambling): Phương pháp này thực hiện việc hoán đổi hoặc xáo trộn vị trí của các giá trị dữ liệu. Ví dụ, từ “code” có thể được xáo trộn thành “node” trong toàn bộ cơ sở dữ liệu.
- Mã hóa (Encryption): Sử dụng thuật toán mã hóa để biến đổi dữ liệu thành dạng không thể đọc được mà chỉ có thể giải mã bởi người có khóa tương ứng. Đây là một phương pháp phức tạp và an toàn, đặc biệt phù hợp cho dữ liệu tĩnh và bảo mật.
- Thay thế (Substitution): Dữ liệu gốc được thay thế bằng các giá trị giả tạo để làm cho dữ liệu không dễ nhận biết. Ví dụ, tên người có thể được thay thế bằng tên ngẫu nhiên.
- Đặt giá trị thành Rỗng (Nulling Out): Khi không còn cách nào khác hoạt động, phương pháp này đặt giá trị dữ liệu thành giá trị rỗng hoặc không có giá trị. Điều này thường được thực hiện để duy trì tính toàn vẹn của cơ sở dữ liệu.
- Xáo trộn (Shuffling): Khác với thay thế, xáo trộn không thay thế giá trị mà thay đổi vị trí của chúng trong cùng cột dữ liệu. Điều này giúp bảo mật dữ liệu trong khi vẫn duy trì tính toàn vẹn của cơ sở dữ liệu.
- Thay đổi giá trị (Value Variance): Phương pháp này sử dụng các hàm để thay đổi giá trị dữ liệu gốc thành giá trị mới, dựa trên các quy tắc xác định.
- Mã giả danh (Pseudonymization): Dữ liệu gốc được thay thế bằng các giá trị giả danh không liên quan đến cá nhân, nhưng vẫn duy trì tính toàn vẹn của cấu trúc dữ liệu.
- Thay đổi giá trị dữ liệu (Data Ageing): Dữ liệu số được thay thế bằng giá trị trung bình của cột tương ứng. Đây thường được sử dụng để bảo vệ dữ liệu cá nhân trong quá trình phân tích.
- Che dấu (Masking): Dữ liệu bị che khuất bằng cách thêm ký tự hoặc dữ liệu giả vào giữa các giá trị, tạo ra một mức độ bảo mật tương đối.
5. Thực tiễn tốt nhất cho kỹ thuật Data Masking

- Xác định Dữ liệu Nhạy Cảm: Bước đầu tiên trong việc thực hiện Data Masking là xác định các yếu tố dữ liệu nhạy cảm trong hệ thống của tổ chức. Điều này bao gồm thông tin cá nhân có thể nhận biết (PII) như tên, địa chỉ, số an sinh xã hội và thông tin tài chính. Hiểu rõ phạm vi và vị trí của dữ liệu nhạy cảm giúp ưu tiên các nỗ lực về Data Masking.
- Phát Triển Chiến Lược Data Masking: Tổ chức nên xây dựng một chiến lược Data Masking toàn diện, định nghĩa mục tiêu, phạm vi và cách tiếp cận cho việc che khuất dữ liệu. Chiến lược này cần xem xét các yêu cầu và quy định cụ thể áp dụng cho ngành công nghiệp của tổ chức, như GDPR hoặc HIPAA, để đảm bảo tuân thủ.
- Sử Dụng Nhiều Kỹ Thuật Che Khuất Khác Nhau: Tùy thuộc vào tính chất dữ liệu và mục đích sử dụng của dữ liệu che khuất, có thể áp dụng nhiều kỹ thuật che khuất khác nhau. Các kỹ thuật thông dụng bao gồm thay thế (thay thế giá trị gốc bằng giá trị hư cấu), xáo trộn (xáo trộn ngẫu nhiên ký tự hoặc số) và mã hóa (sử dụng thuật toán mã hóa để biến đổi dữ liệu). Kết hợp nhiều kỹ thuật che khuất cải thiện tính bảo mật và tính thực tế của dữ liệu che khuất.
- Bảo Tồn Tính Toàn Vẹn Tham Chiếu: Khi che khuất dữ liệu, duy trì tính toàn vẹn tham chiếu là quan trọng để đảm bảo tính nhất quán và khả năng sử dụng của dữ liệu che khuất. Điều này liên quan đến việc bảo tồn mối quan hệ giữa các yếu tố dữ liệu khác nhau, như ràng buộc khoá ngoại, để tránh làm hỏng chức năng ứng dụng hoặc gây hỏng dữ liệu.
- Kiểm Tra và Xác Nhận Quy Trình Che Khuất: Trước khi triển khai Data Masking trong môi trường sản xuất, cần thực hiện kiểm tra và xác nhận cẩn thận. Điều này giúp đảm bảo rằng các kỹ thuật che khuất được áp dụng tạo ra kết quả mong muốn mà không gây ra không nhất quán hoặc dịch vụ bất thường. Quan trọng là liên kết các bên liên quan từ các nhóm khác nhau, như phát triển, kiểm thử và tuân thủ, để xác nhận hiệu quả của quy trình che khuất.
- Triển Khai Kiểm Soát Truy Cập Dựa Trên Vai Trò: Để tăng cường tính bảo mật dữ liệu, tổ chức nên triển khai kiểm soát truy cập dựa trên vai trò (RBAC) cho dữ liệu đã được che khuất. RBAC đảm bảo chỉ những cá nhân hoặc vai trò được ủy quyền mới có thể truy cập các tập dữ liệu che khuất cụ thể. Điều này giúp ngăn chặn truy cập trái phép vào thông tin nhạy cảm, ngay cả bên trong tổ chức.
- Xem Xét và Cập Nhật Chính Sách Che Khuất Thường Xuyên: Data Masking là một quy trình liên tục đòi hỏi việc xem xét và cập nhật thường xuyên. Khi xuất hiện loại dữ liệu mới hoặc quy định mới, tổ chức nên tái đánh giá chính sách Data Masking của mình và điều chỉnh chúng phù hợp. Các đánh giá và kiểm tra định kỳ về triển khai Data Masking giúp xác định bất kỳ thiếu sót hoặc lỗ hổng nào cần được giải quyết.
- Giám Sát và Ghi Nhật Ký Truy Cập Dữ Liệu: Triển khai cơ chế giám sát và ghi nhật ký mạnh mẽ là rất quan trọng để theo dõi việc truy cập dữ liệu và phát hiện bất kỳ hoạt động đáng ngờ nào. Bằng cách theo dõi nhật ký truy cập, tổ chức có thể phát hiện kịp thời các vi phạm bảo mật tiềm năng hoặc các cố gắng truy cập trái phép. Điều quan trọng là thiết lập giao thức rõ ràng để điều tra và phản ứng đối với bất kỳ sự cố bảo mật nào.